The catalog says available. Your team says don't use it.
Available is not the same thing as usable.
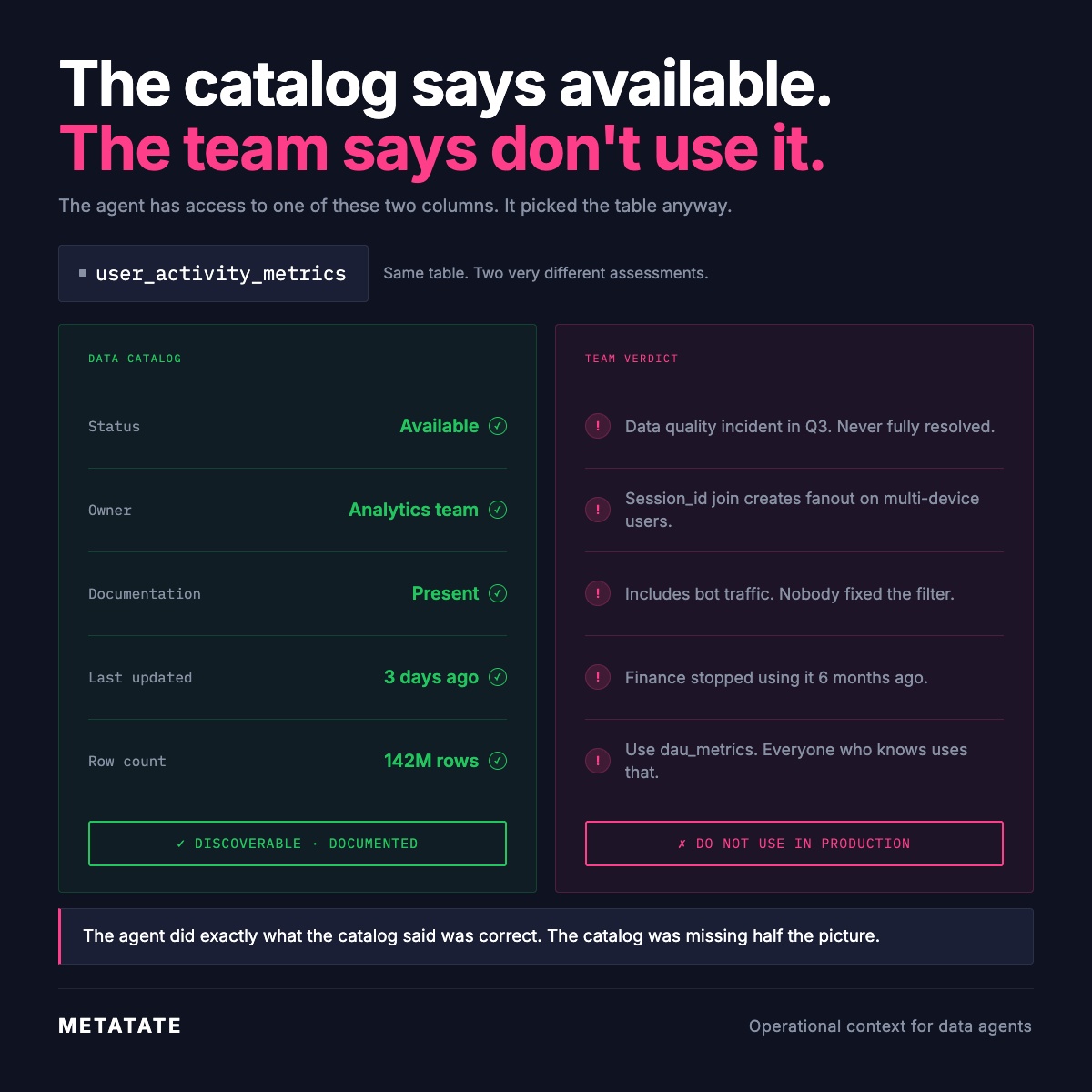
A data catalog can tell you that user_activity_metrics exists, that it has an owner, that it was updated three days ago, and that it has 142 million rows. What it cannot tell you is that Finance stopped using it six months ago, that the session ID join fans out on multi-device users, or that the bot traffic filter was never fixed after Q3.
That knowledge lives somewhere, and it lives in people. Whoever built the table knows. The analyst who got burned by it knows. The team lead who made the quiet decision to stop using it knows. None of that made it into the documentation.
This is a structural property of how operational knowledge works. The things worth knowing about a data asset are often the things that are hard to put in a field: the workarounds, the edge cases, the decisions that made sense at the time and were quietly revised.
When an AI system queries your warehouse, it reads the catalog. It sees the status field. It sees the row count and the documentation badge. It has no way to know what your team knows. The surface looks clean. The system is confident. The query is wrong.
Better catalog fields won't fix this. The knowledge shifts as the data changes, as business definitions evolve, as migrations happen that nobody announces. What's needed is a context layer that captures what the catalog can't: the operational judgment that sits between available and usable.
Next
Related